![]()
All rights reserved. For enrolled students only. Redistribution prohibited.
Linear Systems#
General solution
Matrix exponentials
Free response
Similarity transformation and diagonalization
Stability
Second-order systems
Step response
Solution to a “general” linear system#
Recall that the solution for a first-order (single-variable, i.e., scalar) linear system
where \(A \in \mathbb{R}\) and \(B \in \mathbb{R}\) is given by
Let us now focus on a general case where \(A \in \mathbb{R}^{n\times x}\) and \(B \in \mathbb{R}^{n \times m}\) with \(n \geq 1\) and \(m \geq 1:\)
That is, the state is an \(n\)-dimensional vector and the input is an \(m\)-dimensional vector.
What is the solution in this case? It takes exactly the same form:
But, what is \(e^{At}\) when \(A \in \mathbb{R}^{n \times n}\)?
Definition of matrix exponentials#
For a definition of the matrix exponential \(e^{At}\) (for \(A \in \mathbb{R}^{n \times n}\)), recall the Taylor series expansion for the exponential function \(e^{at}\) (for \(a \in \mathbb{R}\)) around \(t = 0\):
For \(A \in \mathbb{R}^{n\times n}\), the matrix function \(e^{A t}\) is defined by plugging the matrix \(A\) for \(a\) in the above series:
Here \(A^k\) denotes the product of \(A\) with itself \(k\) times:
Verification of the solution to the general linear system#
Given this definition of the matrix exponential, how do we know \(x(t) = e^{A t} x_0 + \int_{0}^{t} e^{A (t - \tau)} B\,u(\tau)\,d\tau\) is a solution to the general linear system \(\dot{x}(t) = A x(t) + B u(t)\) ? See this page.
How to compute the matrix exponential?#
The infinite series above provide a means for computing \(A.\) We will see examples of such computation later. But, such computation can be tedious and sheds little light on the analysis of and design for linear systems. To gain such insight, let’s begin with some special cases where \(A\) is 2-by-2 (pay attention below whether the entries of the matrix are real- or complex-valued).
How are the matrix exponential derived? Check this note for the cases above: Matrix Exponential Derivation
From matrix exponential to free response#
Once the matrix exponential is computed, the free response (the part of the solution that evolves without the effect of an external input) from an initial condition \(x_0 \in \mathbb{R}^n\) can be computed as follows:
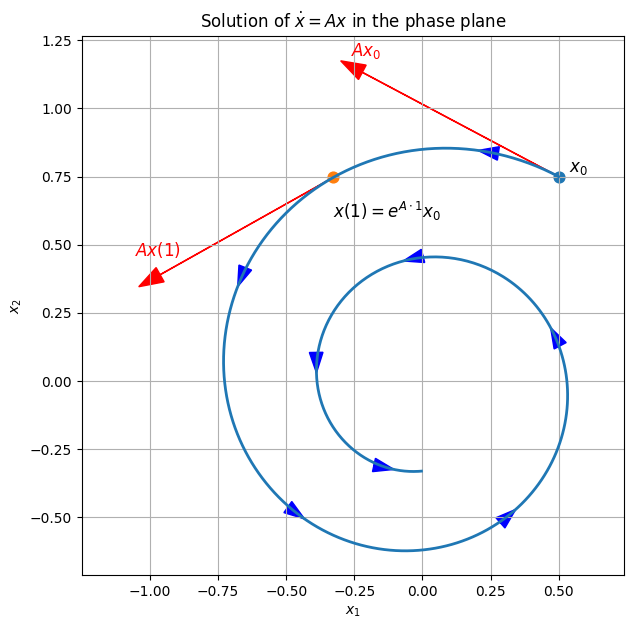
Matrix exponential for a diagonal matrix#
The first of the three special 2-by-2 matrices above was a diagonal matrix (with complex-valued diagonal entries). The form of the matrix exponential generalizes to n-by-n diagonal matrices with complex-valued diagonal entries.
Observe that for this special matrix, the matrix exponential is very straightforward. Can we make use of this fact in computing the matrix exponential of a generic matrix? Before seeing for what kind of matrices we can leverage this observation, let’s first look into how.
Similarity transformations#
Fact from linear algebra: Two n-by-n matrices \(A\) and \(\widetilde{A}\) are called similar if there exists an invertible n-by-n matrix \(P\) such that
or equivalently
For \(A \in \mathbb{C}^{n \times n}\) and \(P \in \mathbb{C}^{n \times n}\) invertible, the following holds.
(In this derivation, we used the fact that \((P^{-1} A P)^k = P^{-1} A^k P\) for \(k = 1,2,\dots\) and \(I = P^{-1} I P\).)
Let’s re-write the end-to-end result:
Now, the question is “what if computing \(e^{\widetilde{A}\, t}\) is easy even if it is not easy for \(e^{A t}\)”? For example, what if \(\tilde A\) is a diagonal matrix? Then, we can compute \(e^{A t}\) in two steps:
First, compute \(e^{\widetilde{A}\, t}\) (it is given above).
Then, muptiply the result by \(P\) (from the left) and \(P^{-1}\) (from the right): \(P\, e^{\widetilde{A}\, t}\, P^{-1}\) to obtain \(e^{A t}\).
Here is a small example:
\(A\) is not in any of the special forms we’ve seen. Let \(P\) be
Then
which is diagonal.
Let’s apply the two steps:
and
Diagonalization#
The next question is, for a matrix \(A,\) when a similarity transformation \(P\) exists such that \(\widetilde{A} = P^{-1} A P\) is diagonal.
One sufficient condition is the following: When the eigenvalues of \(A\) are distinct, then there exists a similarity transformation \(P\) such that \(\widetilde{A} = P^{-1} A P\) is diagonal.
Let \(\lambda_1, \ldots, \lambda_n\) be the eigenvalues of A, and let \(\lambda_1, \ldots, \lambda_n\) be the corresponding eigenvalues. Note that both eigenvalues and eigenvectors can be complex-valued (even when \(A\) is real-valued). Assume that \(\lambda_1, \ldots, \lambda_n\) are distinct. Then, \(\lambda_1, \ldots, \lambda_n\) are linearly independent. And, the similarity transformation \(P\) can be constructed as
Then,
is diagonal (consider \(\Lambda\) as \(\widetilde{A}\) above) where
Let’s look at an example.
The eigenvalues:
The eigenvactors form the the similarity transformation:
Diagonalization \( \Lambda = P^{-1} A P\):
Refresh your memory about the computation of eigenvalues and eigenvectors here.
A =
[[ 7. 0. 5. -5.]
[ 18. 2. 16. -10.]
[ -8. 0. -7. 6.]
[ 0. 0. -2. 1.]]
Eigenvalues =
[ 2.+0.j 1.+2.j 1.-2.j -1.+0.j]
P (eigenvectors as columns) =
[[ 0. +0.j 0.542326+0.j 0.542326-0.j
0. +0.j ]
[ 1. +0.j 0.21693 -0.433861j 0.21693 +0.433861j
0.816497+0.j ]
[ 0. +0.j -0.433861-0.21693j -0.433861+0.21693j
-0.408248+0.j ]
[ 0. +0.j 0.21693 -0.433861j 0.21693 +0.433861j
-0.408248+0.j ]]
Lambda = P^{-1} A P =
[[ 2.+0.j -0.-0.j -0.+0.j -0.+0.j]
[ 0.+0.j 1.+2.j 0.+0.j -0.+0.j]
[ 0.+0.j -0.-0.j 1.-2.j -0.-0.j]
[ 0.+0.j 0.+0.j 0.+0.j -1.-0.j]]
||A P - P Lambda||_F = 3.193462903526722e-15
||Lambda - diag(eigvals)||_F = 1.0595244504700326e-14
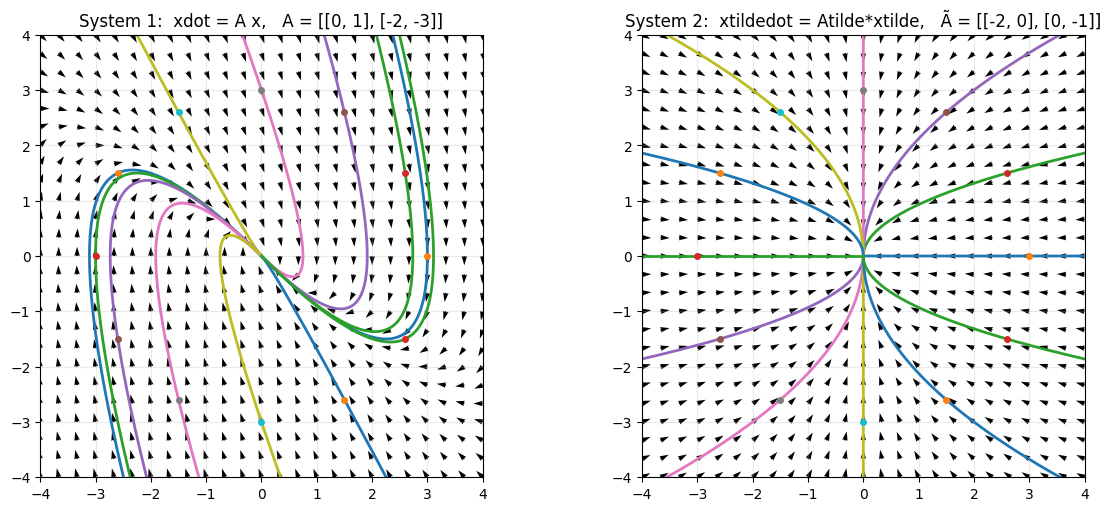
Effect of diagonalization#
A similarity transformation corresponds to a change of coordinates between state variables.
If we define new coordinates \(\widetilde{x}\) by
then solutions of the diagonal system
map directly to solutions of the original system
\(\dot x = A x\).
Diagonalization shows that the apparent coupling in the original system comes from the
coordinate transformation \(P\), not from additional dynamics.
The example below dmeonstrates this observation (using a 2-by-2 matrix and a similarity transformation we introduced earlier).
Stability#
Because similarity transformations only change coordinates and not the underlying dynamics, long-term properties of the system, such as stability and asymptotic behavior, can be determined directly from the diagonalized system.
Let’s focus on the free responses of the system.
where only \(e^{\Lambda t}\) is the only term that changes with time. The matrices \(P\) and \(P^{-1}\) are constant matrices. Let’s take a closer look at \(e^{\Lambda t}\):
Here, \(\lambda_1,\ldots,\lambda_n\) are the eigenvalues of \(A\) and they can be real- or complex-valued.
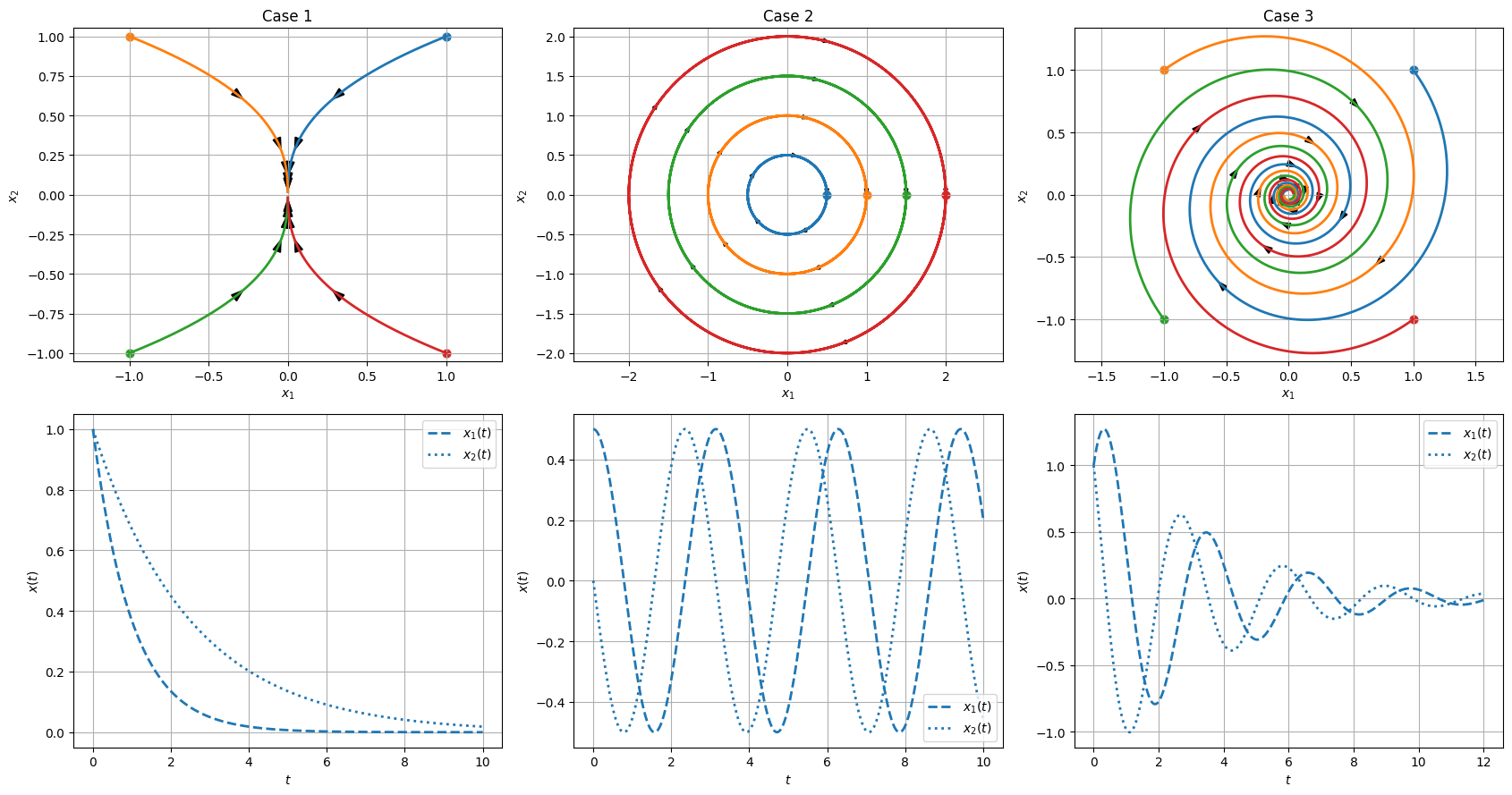
Real-valued eigenvalue \(\lambda\):
To understand the case with complex-valued eigenvalue \(\lambda\), let’s recall a few facts.
If \(\lambda = \lambda_{real} + j \lambda_{imaginary}\) is an eigenvalue, then its complex conjugate \(\lambda_{real} - j \lambda_{imaginary}\) must also be a egeinvalue. (Let’s abbreviate the notation: \(\lambda = \lambda_{r} + j \lambda_{i}\).)
Making use of the Euler’s formula:
\[ e^{\lambda t} = e^{(\lambda_{r} + j \lambda_{i}) t} = e^{\lambda_{r}t} e^{j \lambda_{i} t} = e^{\lambda_{r}t} (cos (\lambda_it)+j sin(\lambda_i t)).\]Then,
\[\begin{split} e^{\lambda t} \;\longrightarrow\; \begin{cases} 0, & \text{if } \operatorname{Re}\lambda < 0,\\[6pt] \text{bounded (oscillatory)}, & \text{if } \operatorname{Re}\lambda = 0,\\[6pt] \infty, & \text{if } \operatorname{Re}\lambda > 0, \end{cases} \qquad \text{as } t \to \infty. \end{split}\]
An important outcome: A necessary and sufficient conditions for the stability of a linear system.
A linear system is stable if and only if,
\[\operatorname{Re}\lambda < 0\]for all eigenvalues \(\lambda\) of \(A\).
The system is unstable if and only if,
\[\operatorname{Re}\lambda > 0\]for some eigenvalue \(\lambda\) of \(A\). (This sentence may be deceptively simple. Make sure that you understand what that means.)
The system is marginally stable if and only if, for all eigenvalues \(\lambda\) of \(A\),
\[\operatorname{Re}\lambda \leq 0\]and for some eigenvalue \(\lambda\) of \(A\),
\[\operatorname{Re}\lambda = 0.\]
Note that these statements are derived under the assumption that \(A\) has distinct eigenvalues. If \(A\) has repeated eigenvalues, the definition for the stable case remains the same. However, the definitions for the other cases change. We will revise these definitions later to capture the case where \(A\) has repeated eigenvalues.
What do these terms mean in terms of the system behavior?
Recall that for the first-order systems, we connected these definitions to the initial conditions and asymptotic behavior. Analogous definitions hold for the general case:
The system is stable if and only if the free response converges to the origin for all initial conditions.
The system is unstable if and only if the magnitude of the free response diverges to infinity for some initial condition.
The system is marginally stable if and only if the magnitude of the free response is bounded for all initial conditions, and the free response does not converge to the origin for some initial condition.
Essentially, decay corresponds to stability, bounded (oscillatory) behavior corresponds to marginal stability, and growth corresponds to instability.
Block diagonalization#
Can we always diagonalize the \(A\) matrix? We may not be able to diagonalize fully, but we can get very close.
Let \(A \in \mathbb{R}^{n \times n}\).
There exists an invertible matrix \(P\) such that \(P^{-1} A P = J\), where
and
and \(n_i\) is the algebraic multiplicity of eigenvalue \(\lambda_i\).
When all eigenvalues are distinct, then \(n_i = \) for all eigenvalues and full diagonalization is possible.
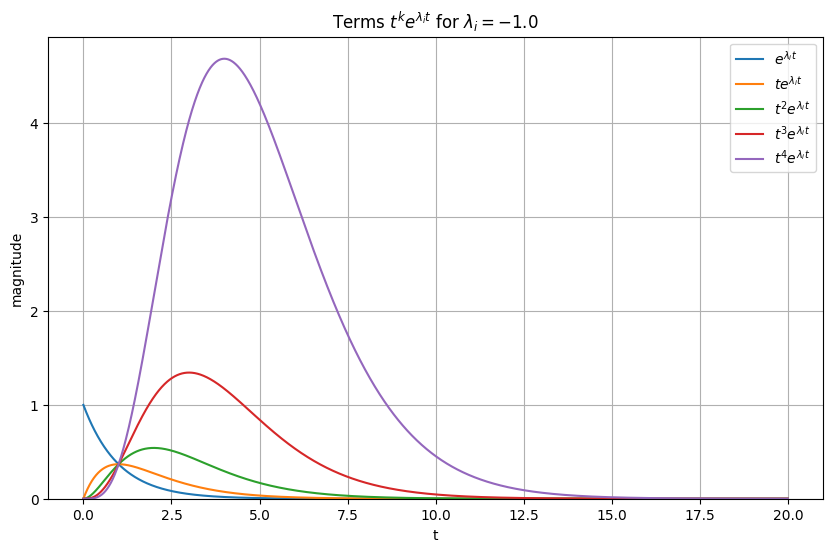
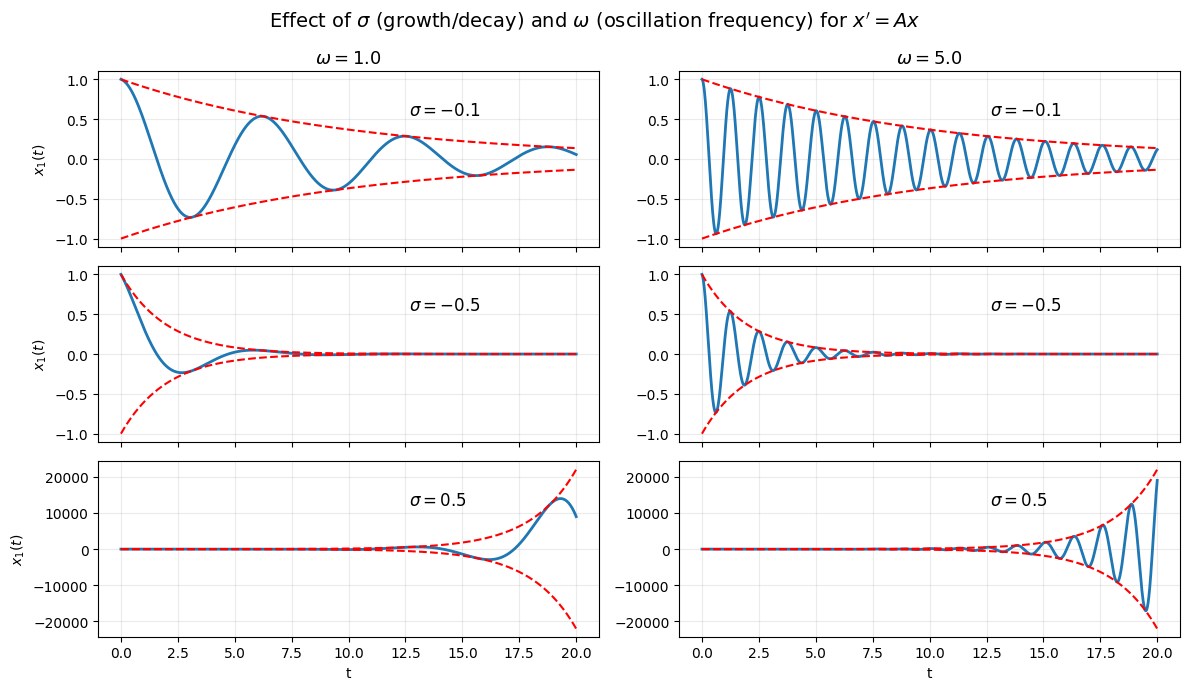
It is straightforward to derive the matrix exponential for \(J\) in terms of the matrix exponential of the diagonal blocks \(J_1,\ldots, J_p\):
And, \(e^{J_i t}\) has the structure (see Matrix Exponential Derivation: Special Case):
The entries involve terms of the form
Simulation below allows you to explore these functions for different values of \(\lambda\).
Although polynomial factors such as \(t^k\) can cause significant transient growth in the solutions, the long-term behavior is still governed by the exponential term \(e^{\lambda t}\). When \(\operatorname{Re}(\lambda) < 0\), the exponential decay dominates any polynomial growth, and all solutions decay to zero as \(t \to \infty\).
As a result, the presence of repeated eigenvalues or non-diagonalizable dynamics does not change the stability classification of the system. Stability depends only on the real parts of the eigenvalues, not on the polynomial factors that appear in the solution.
Stability for systems with repeated eigenvalues#
If the \(A\) matrix has repeated eigenvalues, the stability definitions using the eigenvalues change depending on the shape of the \(J\) matrix and whether these repeated eigenvalues are on the imaginary axis.
A linear system is stable if and only if
\[\operatorname{Re}\lambda < 0\]for all eigenvalues \(\lambda\) of \(A\).
The system is unstable if and only if, for some eigenvalue \(\lambda\) of \(A\),
\[\operatorname{Re}\lambda > 0,\]or for some eigenvalue \(\lambda\) that has a Jordan block of size strictly greater than 1
\[\operatorname{Re}\lambda = 0.\]The system is marginally stable if and only if, for all eigenvalues \(\lambda\) of \(A\),
\[\operatorname{Re}\lambda \leq 0,\]and the Jordan block size is 1 for all eigenvalues \(\lambda\) of \(A\) such that
\[\operatorname{Re}\lambda = 0.\]
For example, a system with
which has a repeated eigenvalue at \(0\). Since the the corresponding Jordan block has size \(2\), the system is unstable. Note that the unstability is due to the growing \(te^{0t}\) term in the free response.
Consider a system with
which has a repeated eigenvalue at \(0\). Since the corresponding Jordan blocks have size \(1\), the system is marginally stable. In fact, \(\dot{x} = [0,0]^{\top}\), meaning that the system remains at its initial condition.
Modes of a linear system#
(The following observation generalizes to the case when \(A\) cannot be fully diagonalized but let us consider the case in which it can be for clarity.)
Recall that
The free response is a linear combination of the functions \(e^{\lambda_1 t}, \ldots, e^{\lambda_n t}.\) (Note that some of the eigenvalues may be complex along with their complex congugates. We will develop a cleaner interpretation of that case later. For now, let’s proceed with potentially complex entries in the diagonal matrix exponential.)
We refer to \(e^{\lambda_1 t}, \ldots, e^{\lambda_n t}\) as the modes of the system.
We will look into an example on how the modes of a linear system determine the free response of a linear system. It may be useful to recall that the columns of the transformation \(P\) are the eigenvectors of \(A\):
and any initial condition \(x_0\) can be written as a linear combination of \(v_1,\ldots, v_n\).
Note that \(A\) is fully-diagonalizable and, therefore, \(v_1,\ldots, v_n\) are linearly independent. It implies that the coefficients of the linear combination are unique. Let
where \(c = [c_{1}, \ldots, c_{n}]^{\top}\) is the vector of coefficients. This implies \(c = P^{-1}x_{0}\). Recall that
Substituting \(c = P^{-1}x_{0}\), we get
After some matrix algebra, \(x(t)\) can be represented as
The free response is a superposition of eigenmodes, each scaled by how strongly the initial condition projects onto its eigenvector and evolving according to the associated eigenvalue.
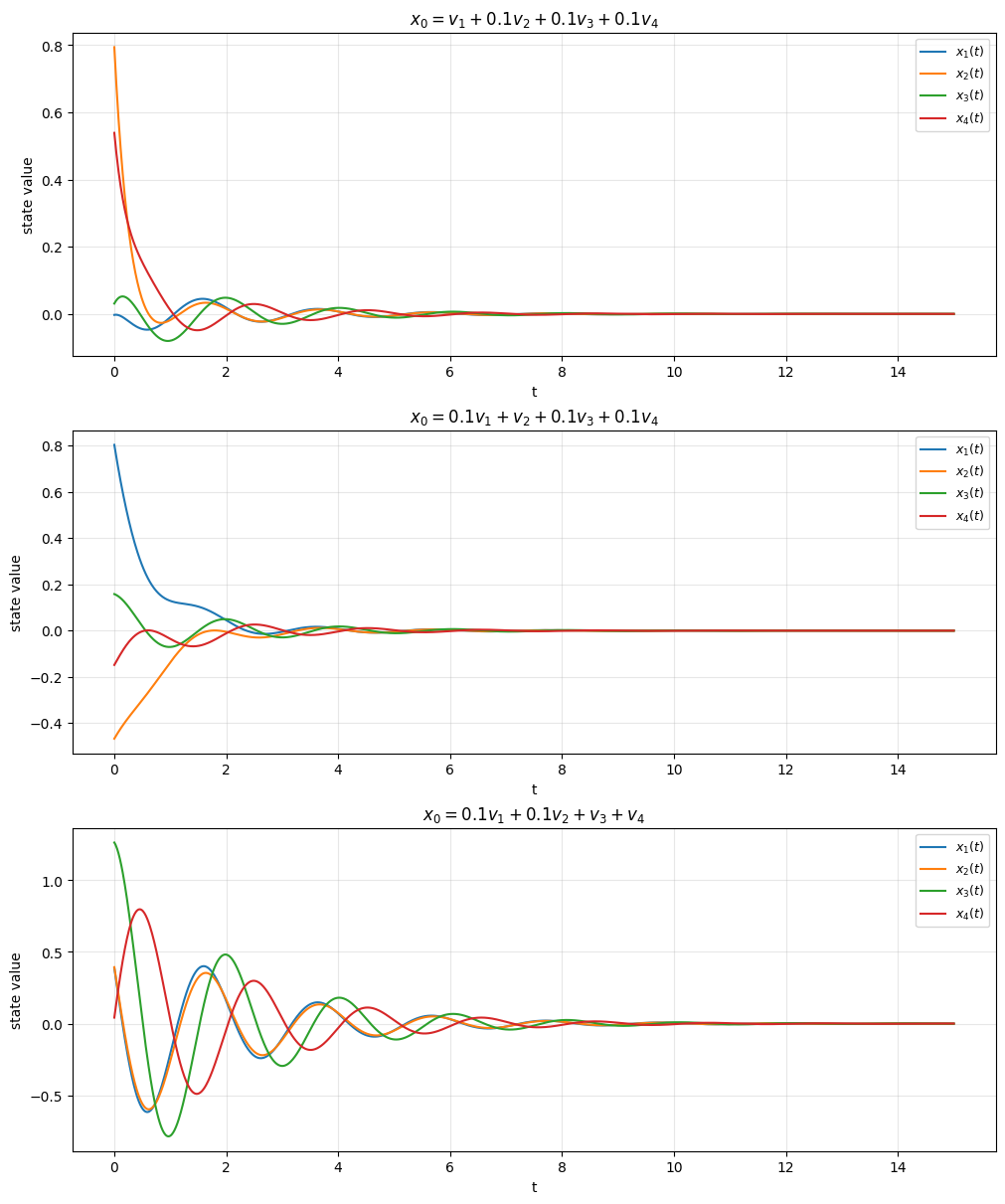
What is the implication? The free response of the system depends on the coefficients of the modes. For example, if the initial state has no components in the subspace spanned by the complex eigenvalues (\(c_{i} = 0\) for all \(λ_{i}\) such that \(\text{Im}(λ_{i}) \neq 0\)), then the free response does not oscillate. More importantly, the convergence of the free response depends on the initial state. If, the initial state
has a component in the subspace spanned by the unstable modes (\(c_{i} \neq 0\) for some \(λ_{i}\) such that \(\text{Re}(λ_{i})>0\)), then the free response diverges,
has no component in the subspace spanned by the unstable and marginally stable modes (\(c_{i} = 0\) for all \(λ_{i}\) such that \(\text{Re}(λ_{i})\geq 0\)), then the free response converges to 0.
Remark on stability vs. convergence of a particular initial state: The above discussion describes the convergence behavior from a particular initial state, whereas stability is a system-level property that concerns all initial states. Remember that stability can be verified by checking only the eigenvalues.
We may have a system that is not stable (\(\text{Re}(\lambda_{i}) \geq 0\) for some \(λ_{i}\)), but the free response converges to \(0\) for some initial condition.
Note that we did not encounter such cases for first-order systems since there is only one eigenvalue (the scalar \(A\)) and one eigenvector (any non-zero reel number, e.g., \(1\)). For an unstable first-order system (\(A > 0\)), the subspace spanned by the unstable mode is \(\mathbb{R}\), and all non-zero initial conditions lie in this space. Consequently, all non-zero initial conditions diverge.
Eigenvalues:
[-3.79408178+0.j -1.64231316+0.j -0.48180253+3.08840707j
-0.48180253-3.08840707j]
A closer look at second-order systems#
It is worth taking a closer look into second-order systems for intuition:
By now, we have established that the eigenvalues of \(A\) play a central role. For \(A \in \mathbb{R}^{2 \times 2}\), there are several possibilities:
Real and distinct eigenvalues: \(\lambda_1\) and \(\lambda_2\). In this case, \(A\) can be diagonalized to
Complex eigenvalues, \(\lambda\) and \(\lambda^*\), since complex eigenvalues come in complex conjugate pairs.
Repeated eigenvalues, \(\lambda\) and \(\lambda\), which have to real since they are same. In this case, there are two possibilities.
\(A\) can be fully diagonalized, which boils down to case 1 above. \begin{bmatrix} \lambda & 0 \ 0 & \lambda \end{bmatrix}
\(A\) can transformed into a different special case: \begin{bmatrix} \lambda & 1 \ 0 & \lambda \end{bmatrix}
Let’s therefore focus on the first two cases.
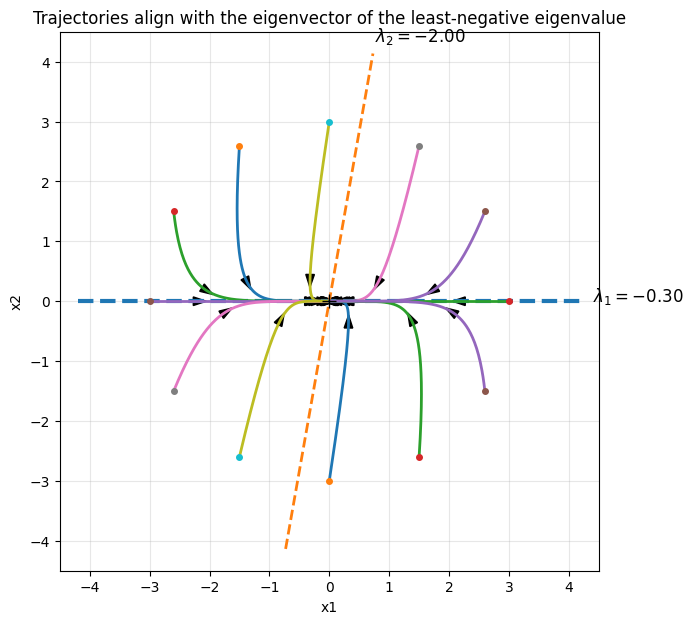
Case 1: Assume that \(A \in \mathbb{R}^{2 \times 2}\) has two distinct real eigenvalues \(\lambda_1\) and \(\lambda_2\) with corresponding eigenvectors \(v_1\) and \(v_2\).
Then,
The solution is therefore a linear combination of \(e^{\lambda_1 t}\) and \(e^{\lambda_2 t}\).
Suppose the initial condition can be written as
Then,
(See the example below for a geometric interpreations of this last observation.)
Case 2: This is the case with complex eigenvalues. The reasoning in case 1 carries over but working with complex eigenvalues and eigenvectors may not be as intuitive. For a more intuitive representation, we need a few more facts.
Let
where \(v_R, v_I \in \mathbb{R}^2\).
The eigenvalue–eigenvector equation
can be written as
Expanding both sides gives
Equating real and imaginary parts yields
These equations can be rewritten compactly as
Define
Then
and equivalently,
Does
look familiar?
We can write
Therefore, the solution of
can be expressed as
The solution is a linear combination of
Some observations about second-order systems#
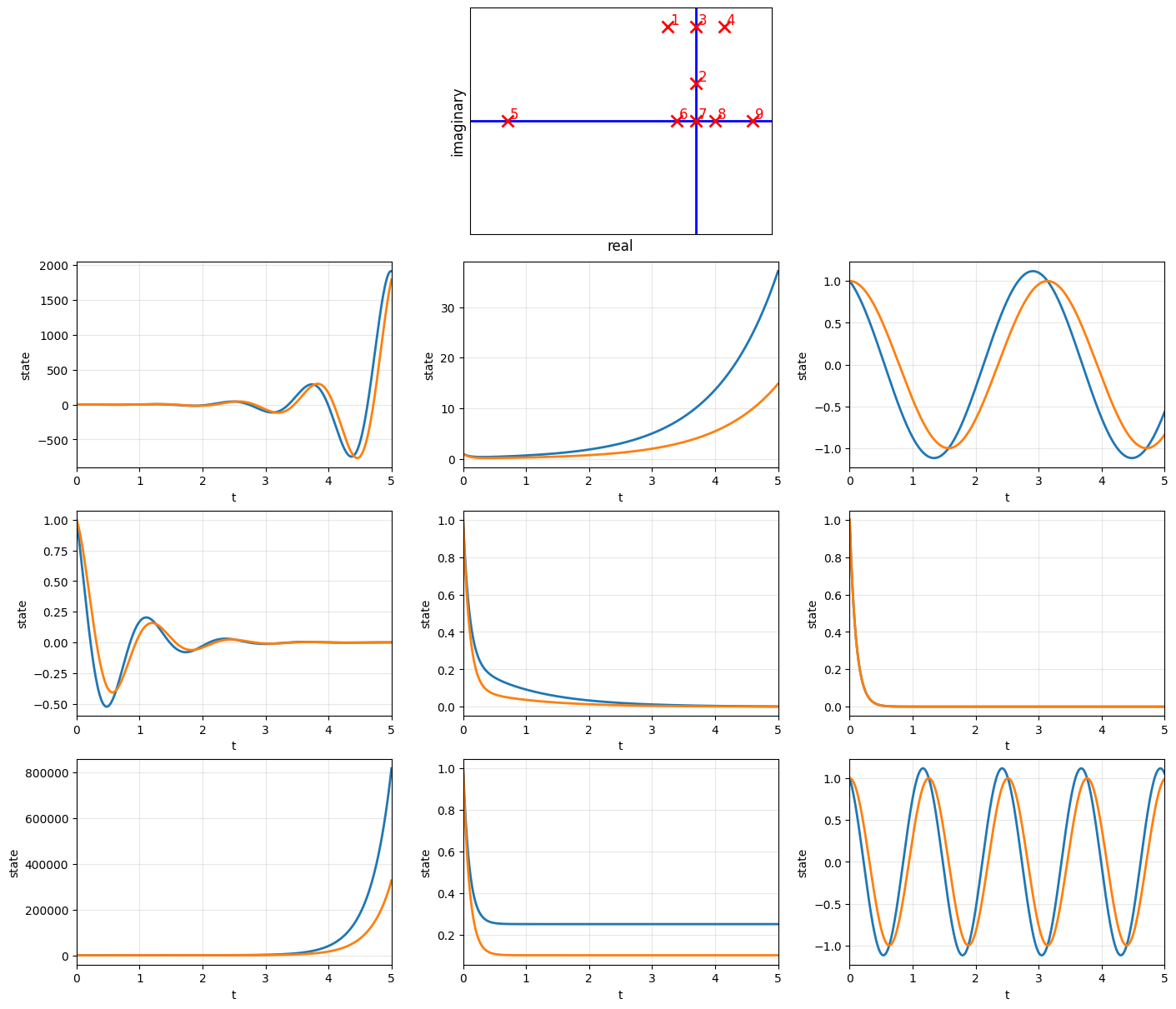
The free response for a first-order system could include terms of the form of \(e^{a t}\) where \(a\) is a real number. Therefore, it can not include oscilations.
The free response for a second-order system may or may not include oscillations.
If the eigenvalues are real, the response is a combination of two first-order systems; hence, does not have oscilations.
If the eigenvalues are complex, the system has oscillations.
The following example focuses on classifying second-order systems with respect to their eigenvalues.
Alternative represenations of second-order systems#
We will work with second-order system quite often. It is therefore useful to familiarize ourselves with two related alternative representations.
The first one simplies stability checks. The second-order system
is asymptotically stable if and only if \(\alpha >0\) and \(\beta >0\).
Here is an explanation of why.
The second one gives an interpretation about intuitive quantities that we often encounter in mechanical or electrical systems.
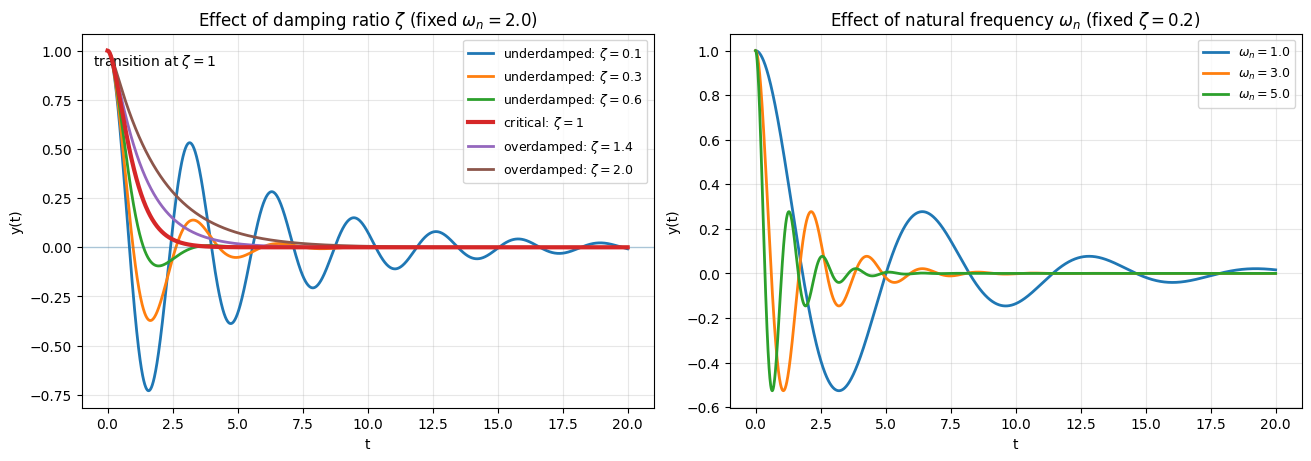
Consider the second-order system
The roots of the resulting characteristic polynomial are
Here,
\(\zeta\) is the damping ratio, and
\(\omega_n\) is the natural frequency.
Step response for linear systems#
Consider the linear time-invariant (LTI) state-space system
with initial condition
The matrices have compatible dimensions:
Let \(u\) be a step input of the form
where
Recall that, for the scalar case with
the step response was
and
For the general case, the step response looks similar modulo we have to pay attention to matrices. Starting from the general solution of the state equation,
and considering a step input
we obtain
Factor out \(e^{A t}\) from the integral:
Evaluating the matrix integral (assuming \(A\) is invertible, and when the system is stable \(A\) is invertible),
which gives
Substituting back,
Finally, simplifying,
Using the output equation
and substituting the expression for \(x(t)\),
we obtain
Rearranging terms,
Grouping the exponential terms,
Equivalently, this can be written as
Steady-state response under a step input#
Recall
When does a steady-state value exist?
If
then
Therefore the transient term \(C e^{At}(\cdot)\) vanishes, and the output converges to a constant.
As \(t\to\infty\), \(y(t)\) approaches
Note that \(y_{ss}\) does not depent on \(x_0\).
When \(u,y\in\mathbb{R}\) (single-input, single-output), \(\bigl(D-CA^{-1}B\bigr)\) is a scalar, and
so the steady-state gain from \(u\) to \(y\) is
Example: Steady-state gain for a second-order system (in an “alternate” form)#
Consider the second-order system
where \(\bar{u}\) is a constant (step) input.
Assume the system is stable, i.e.,
Let us obtain a state space representation and apply the result we derived above. Define the state variables
Then the system can be written in state-space form as
with output
Check whether the outcome here will depend on the choice of the states.
Since the system is stable, the steady-state output exists. Using the steady-state gain formula,
we obtain
Thus, the steady-state gain from the input \(\bar{u}\) to the output ( y ) is
This provides a simple way to compute the steady-state gain for second-order systems in this alternative form.
Matching exercise: step responses of a second-order system#
Consider the second-order system
with unit-step input \(u(t)=1\) for \(t\ge 0\) and zero initial conditions.
The figure below shows 12 step responses, generated using the parameter sets
For each subplot (System 1–12), identify the corresponding values of \(\zeta\), \(\omega_n\), and \(b\).
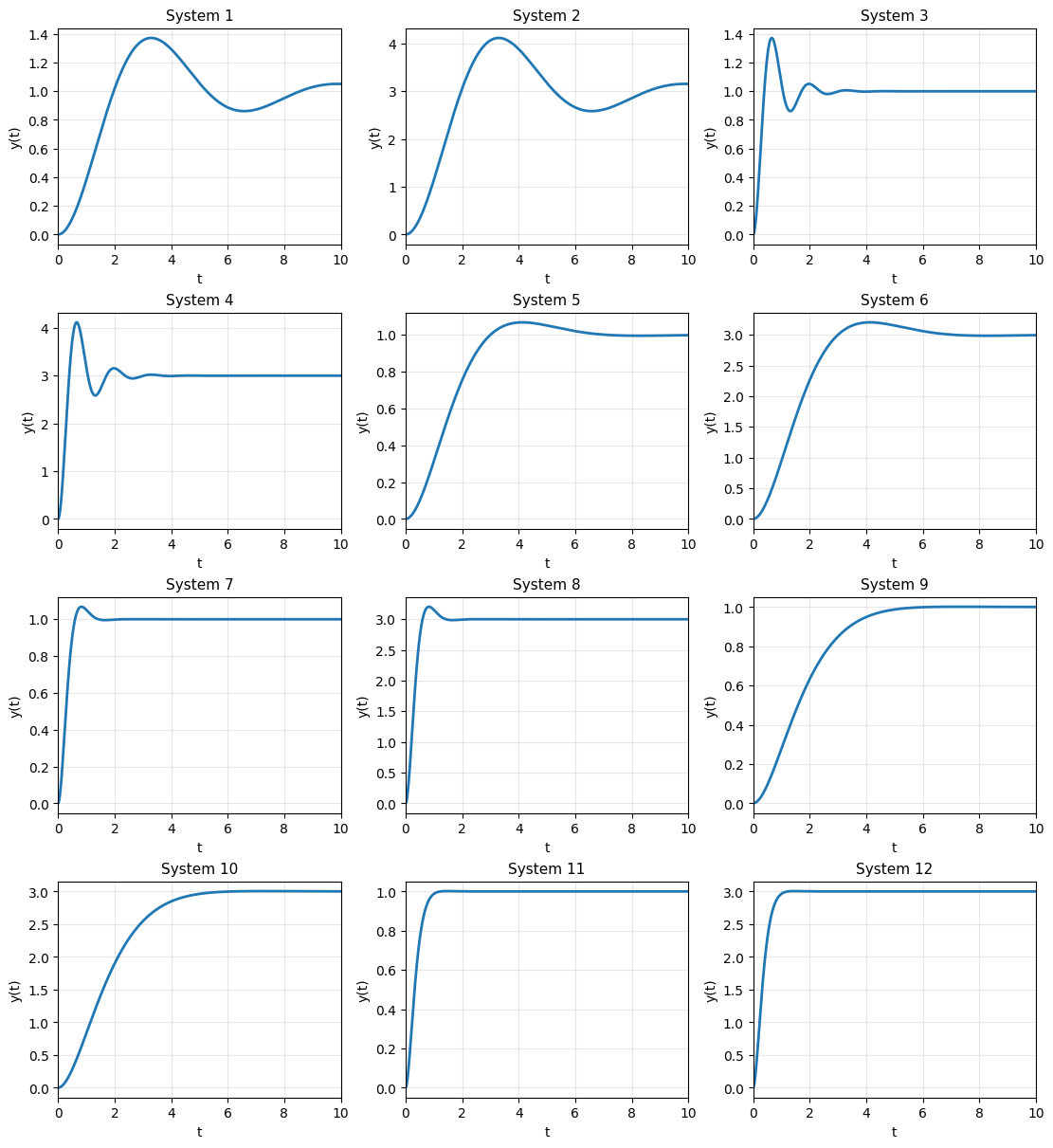
| ζ | ωₙ | b | |
|---|---|---|---|
| System | |||
| 1 | 0.30 | 1.0 | 1.0 |
| 2 | 0.30 | 1.0 | 3.0 |
| 3 | 0.30 | 5.0 | 1.0 |
| 4 | 0.30 | 5.0 | 3.0 |
| 5 | 0.65 | 1.0 | 1.0 |
| 6 | 0.65 | 1.0 | 3.0 |
| 7 | 0.65 | 5.0 | 1.0 |
| 8 | 0.65 | 5.0 | 3.0 |
| 9 | 0.90 | 1.0 | 1.0 |
| 10 | 0.90 | 1.0 | 3.0 |
| 11 | 0.90 | 5.0 | 1.0 |
| 12 | 0.90 | 5.0 | 3.0 |